Flexible Schemas with PostgreSQL and Elasticsearch
At the day job, I am in the process of migrating a number of applications off of a document store to postgres. One of the features we had was custom attributes which effectively allowed end users to associate arbitrary data with various entities. In addition to just porting the ability to store user defined data, we now need to allow end users to be able to query for the associated entity via the attributes they have defined. This includes ability to sort by, apply range (numeric or date) filters and do full text phrase matching over text values.
For example, ACME Co., may want to define attributes about their users like this:
- ip_address (text)
- name (text)
- login_date (timestamp)
- max_sale_value(number)
- total_purchases(number)
- vip_customer (boolean)
From this data they might want ask arbitrary questions of this data to find and gain insights of users. For example
Find all users who have logged in within the last 3 months, have more than 10 total purchases but are not vip and whose name starts with J
Translated roughly to SQL:
SELECT *
FROM user_attributes
WHERE
login_date BETWEEN NOW() - INTERVAL '90 DAY' AND NOW()
AND total_purchases > 10
AND name ILIKE 'j%'
AND vip = FALSE
Another company, WizzBang LLC., want to store a different set of data
- name (text)
- phone_number (text)
- dog_lover (boolean)
- cat_lover (boolean)
- pet_count (number)
- first_pet (timestamp)
- favorite_dog_breed (text)
- favorite_cat_breed (text)
- award_count (number)
Not only is the data they store very different both physically and contextually, but the are going to ask very different questions of it than ACME. Of course, they are both large companies and estimated ~10M users. This means we are going to need a way to index their data to support the queries they will need to run so the application doesn't grind to a stop. There are some options out there.
EAV
The Entity Attribute Value (EAV) design has been around for a while. It has pros and cons. For our situation, on the upside, the column that stores the actual value is a physical, typed column that we can perform a variety of operations on. Additionally, because it is a column, we could index it for better performance.
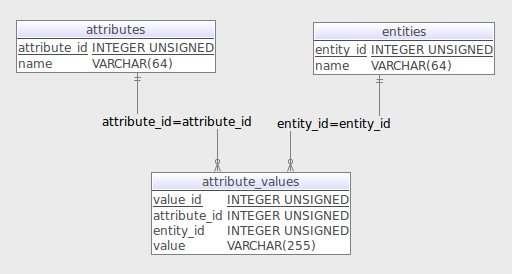
EAV schemas try to make the rigid relational model and make it bit more flexible. An entities table defines basic things (Car). An attributes table defines the properties of an entity (weight), and the attribute_values table holds the value for a property associated with an entity. For our needs, the primary problem is that there is only a single value column, meaning they all have to be the same type. That makes it hard to support dates, boolean, or numeric types.
JSON (JAY'sun) -n., noun
We can serialize our data as JSON and everything will be easy
- An open-standard file format that uses human-readable text to transmit data consisting of attribute-value pairs and array data types
JSON
You might be thinking JSON! think again. If all we needed to do was store the data, you might be on to something. But we have to do a bit more with it and this gets hard. In particular:
- It is really just text under the hood which means we have to do a lot of manual type casting of specific fields and doing that won't use indexes (slow)
- To be able to do any kind of searching, range queries, etc, we need to know what kind of data is in there anyway. And if we have to control that - we might as well just use a table
- Doing joins off of values in JSON columns is tough. We either have to add columns to the table to help out, or put the JSON column on the source table to avoid having to do join - like a doc store
The real deal breaker is doing queries that target specific fields within the JSON need to know what kind of data is in the field and explicitly cast it to perform any kind of filtering other than exact matching.
-- SAMPLE TABLE w/ JSON COLUMN
CREATE TABLE sample(
id SERIAL
, word TEXT
, json_data JSONB NOT NULL
);
CREATE INDEX json_data_gin_indx ON sample USING GIN(json_data);
--- INSERT SOME RANDOM DATA
INSERT INTO sample (word, json_data)(
SELECT
encode(gen_random_bytes(10), 'hex')
, JSON_BUILD_OBJECT(
'value', iter
, 'sample', encode(gen_random_bytes(10), 'hex')
) from generate_series(1, 2000000) as iter
)
-- > Affected rows: 2000000
-- > Time: 76.108s
-- TRY TO QUERY FOR SOME VALUES
select *
from table_b
where json_data->>'a' < 2
-- > ERROR: operator does not exist: text < integer
while the ->> operator gets you access to field values within the JSON, they are accessed by the string representation, which greatly limits the ways it can be queried. To get around the issue you would have to manually cast all fields
select *
from table_b
where
CAST(json_data->>'a' AS INTEGER) < 2
This isn't very complicated to do itself, and it will work a short while. The problem here is that this kind of query can't make use of indexes. While it is possible to index JSON columns with GIN indexes, You are fairly limited when it comes to the kinds of queries will make use of indexes. Once the table grows large enough, we are going to need a different solution
What we really want is an actual postgres table with typed columns that gives us all of the powerful query predicate and indexing power that we know and love. I want a flexible schema. To get the functionality we need to implement the described feature, we're going to need to rethink this.
Attribute Table
This is actually a pretty good use case for table inheritance. PostgreSQL table inheritance takes a page directly from object orientated programming practices. Tables can inherit columns and attributes from a common parent table. Every child table will have all of the columns that are added or removed from the parent but are still able to define their own columns to make up a unique schema. This is how we can achieve a flexible schema with physical tables. We can make this process mostly automatic with triggers.
-- base table
CREATE TABLE custom_attributes (
id UUID NOT NULL default gen_random_uuid()
, user_id UUID NOT NULL
, created_at TIMESTAMPTZ DEFAULT NOW()::TIMESTAMPTZ
, company_id UUID NOT NULL
);
-- TRIGGER: When a new company record is inserted
-- Generate an attribute table for there custom data
CREATE OR REPLACE FUNCTION generate_custom_attribute_table()
RETURNS TRIGGER AS $$
DECLARE
tablename TEXT;
ident TEXT
company_id TEXT
BEGIN
company_id := COALESCE(NEW.id, gen_random_uuid())::TEXT;
ident := REPLACE(company_id, E'\-', ''::TEXT);
tablename := 'user_attributes_' || ident;
EXECUTE FORMAT(
'CREATE TABLE %s (
CONSTRAINT %s_pkey PRIMARY KEY (user_id, company_id)
) INHERITS (custom_attributes)'
, tablename, tablename
)
RETURN NULL;
END;
$$ LANGUAGE plpgsql VOLATILE;
CREATE TRIGGER on_company_insert
AFTER INSERT
ON company FOR EACH ROW
EXECUTE procedure generate_custom_attribute_table();
When a new record is inserted into the company table, a trigger creates a table that inherits from the custom_attribute table. This is the table that will contain the physical columns to store data points defined by a company. Initially, this table doesn't have any columns that deviate from the base table.
Now, we are going to need a way to allow administrators to manage their schema with out giving them direct access to the internal table. For that we are going to need a catalog that keeps record of the field names and their respective types that can be used as the public interface.
Catalog Table
We'll store the attributes definitions our companies want to store in a table that we can simply add / remove records from. Basically all we need is the name of the field and the type of data that will be stored - In this case we are going to constrain that to just number, boolean, text and date fields.
CREATE DOMAIN user_attribute_type AS TEXT
CONSTRAINT user_attribute_field_chk
NOT NULL CHECK(VALUE IN ('boolean', 'date', 'number', 'text'));
CREATE TABLE IF NOT EXISTS user_attribute_catalog (
id UUID NOT NULL gen_random_uuid()
, company_id UUID NOT NULL REFERENCES company(id)
, field_name text NOT NULL
, field_type user_attribute_type
, created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
, CONSTRAINT catalog_attribute_name_uniq (company_id, field_name)
);
When we want to show all of the defined attributes for a company, it is a pretty simple query
SELECT field_name, field_type
FROM user_attribute_catalog
WHERE company_id = $1
The last piece to this is going to be a couple of triggers to add and remove the appropriate columns to the child table when records are added or removed from the catalog table.
Inserting a record into the catalog table adds a column to the respective attribute table for the company. The type of the column is determined by the field_type column of the inserted record
| Field Type | Column Type |
|---|---|
| date | TIMESTAMPTZ |
| boolean | BOOLEAN |
| number | FLOAT8 |
| text | zdb.fulltext |
-- ADD ATTRIBUTE
CREATE OR REPLACE FUNCTION public.add_user_attribute()
RETURNS TRIGGER AS $$
DECLARE
statements TEXT;
tablename TEXT;
ident TEXT;
organization_id TEXT;
field TEXT;
BEGIN
ident := REPLACE(NEW.company_id::TEXT, E'\-', ''::TEXT);
tablename = 'user_attributes_' || ident;
field := NEW.field_name || '_' || ident
IF
NEW.field_type = 'boolean' THEN
statements := FORMAT('
ALTER TABLE %s
ADD COLUMN IF NOT EXISTS %s BOOLEAN
', tablename, field);
ELSEIF NEW.field_type = 'number' THEN
statements := FORMAT('
ALTER TABLE %s
ADD COLUMN IF NOT EXISTS %s FLOAT8
', tablename, field);
ELSEIF NEW.field_type = 'date' THEN
statements := FORMAT('
ALTER TABLE %s
ADD COLUMN IF NOT EXISTS %s TIMESTAMPTZ
', tablename, field);
ELSEIF NEW.field_type = 'text' THEN
statements := FORMAT('
ALTER TABLE %s
ADD COLUMN IF NOT EXISTS %s zdb.fulltext
CONSTRAINT ua_%s_chk CHECK(char_length(%s) <= 512)
', tablename, field, field, field);
ELSE
RAISE EXCEPTION 'Unknown attribute type: %s', NEW.field_type;
END IF;
EXECUTE statements;
RETURN NULL;
END;
$$
LANGUAGE plpgsql VOLATILE;
CREATE TRIGGER on_insert_user_attribute_fields
AFTER INSERT
ON user_attribute_fields FOR EACH ROW
EXECUTE PROCEDURE add_user_attribute();
-- REMOVE ATTRIBUTE
CREATE OR REPLACE FUNCTION public.remove_user_attribute()
RETURNS TRIGGER AS $$
DECLARE
tablename TEXT;
ident TEXT;
field TEXT;
BEGIN
ident := REPLACE(OLD.company_id::TEXT, E'\-', ''::TEXT);
tablename := 'user_attributes_' || ident;
field := OLD.field_name || '_' || UUID_TO_IDENT(OLD.id);
EXECUTE FORMAT('
ALTER TABLE %s
DROP COLUMN IF EXISTS %s
', tablename, field);
RETURN NULL;
END;
$$ LANGUAGE plpgsql VOLATILE;
CREATE TRIGGER on_delete_user_attribute_fields
AFTER DELETE
ON user_attribute_fields
FOR EACH ROW
EXECUTE PROCEDURE remove_user_attribute();
These two trigger functions handle managing the internal table definition that will hold the actual attribute data. When a record is inserted into the catalog table, a column is added. Conversely, when record is deleted from the catalog, it corresponding column is removed.
It is important to note that the column being added and removed have no constraints and no defaults. Doing it this way avoids having to re-write entire tables and is mostly a change in the metadata about the table. These operations can be preformed on production tables with multiple millions of records in milliseconds.
Inserting into the Company table will generate an attributes table specifically for that company
INSERT INTO company (id, name)
VALUES ('02335c58-a66f-4b53-9801-cb8045e2e848', 'ACME');
# list tables
\dt
company
custom_attributes
custom_attribute_catalog
user_attributes_02335c58a66f4b539801cb8045e2e848
By default, it will only have the columns that were defined by the parent attributes table.
# user_attributes_02335c58a66f4b539801cb8045e2e848
+-------------+------+
| Column Name | Type |
| ----------- | ---- |
| id | UUID |
| company_id | UUID |
| user_id | UUID |
+-------------+------+
Adding a field definition to the catalog adds a column of the appropriate type to the child table that was set up for the specific company.
INSERT INTO user_attribute_catalog
(company_id, field_name, field_type)
VALUES (
'02335c58-a66f-4b53-9801-cb8045e2e848'
, 'fake_number'
, 'number'
);
# user_attributes_02335c58a66f4b539801cb8045e2e848
+----------------------------------------------+--------+
| Column Name | Type |
|----------------------------------------------|--------|
| id | UUID |
| company_id | UUID |
| user_id | UUID |
| fake_number_6ad3e88314e04832b39daef8fa7ff730 | DOUBLE |
+----------------------------------------------+--------+
Removing records for from the catalog table will additionally drop the column from the attribute table
Indexing
 We've solved the flexible schema problem, but we still have the issue of needing to perform complex user defined queries on a large data set. We need to index this, and to do that we are going to use elasticsearch via the fantastic zombodb extension.
We've solved the flexible schema problem, but we still have the issue of needing to perform complex user defined queries on a large data set. We need to index this, and to do that we are going to use elasticsearch via the fantastic zombodb extension.
Once the extension is installed and configured, we need to update the first trigger that generates the attributes table to add an elasticsearch index.
It is an index like any other postgres index, it just happens to live in elasticsearch
BEGIN
company_id := COALESCE(NEW.id, gen_random_uuid())::TEXT;
ident := REPLACE(company_id, E'\-', ''::TEXT);
tablename := 'user_attributes_' || ident;
EXECUTE FORMAT(
'CREATE TABLE %s (
CONSTRAINT %s_pkey PRIMARY KEY (user_id, company_id)
) INHERITS (custom_attributes);
CREATE INDEX IF NOT EXISTS %s_zdx ON %s USING zombodb((%s.*)) WITH (alias = ''%s'')
'
, tablename, tablename, tablename, tablename, tablename, tablename
);
RETURN NULL;
END;
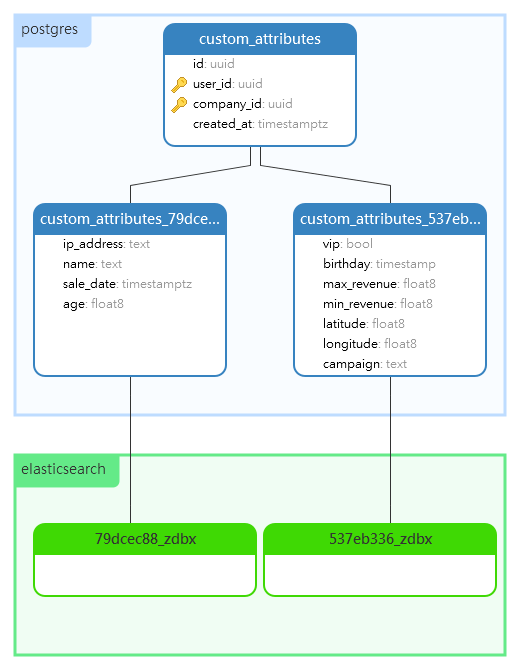
That is all there is to it. The simplest way to think about how zombodb and postgres work together is this - It is an index like any other postgres index, it just happens to live in elasticsearch; In the same way postgres manages a BTREE index on disk, it will manage a zombodb index in elasticsearch. Zombodb indexes the entire row, so as columns are added and values are populated, the index is kept up to date. This means we can perform just about any kind of search query elasticsearch supports. We can update the SQL query for the data set defined for ACME to use zombodb
SELECT *
FROM user_attributes_02335c58a66f4b539801cb8045e2e848
WHERE user_attributes_02335c58a66f4b539801cb8045e2e848 ==>
dsl.limit(25,
dsl.must(
dsl.term('vip', 'false')
, dsl.range(field=>'total_purchases', gt=>10)
, dsl.range(
field=>'login_date'
, lte=>'2018-12-30'
, gte=>'2018-09-30'
)
, dsl.wildcard('name', 'j*')
)
)
This tells PG to use the zombodb index which makes the appropriate query to your elasticsearch cluster, and will still return the results out of the table. You can still use joins, procedures and everything else postgres provides. We get a strongly typed flexible schema in a relational database backed by a blazing fast elasticsearch index.
It may not be magic - but it is damn close