Distributed Timers With Node.js and Skyring
orking with timers a distributed system is a really nasty problem that pops up more often than most people would like. Something as simple an useful as setTimeout / clearTimeout becomes brittle, unreliable and a bottle neck in today's stateless, scalable server mindset. Basically, I need to be able to set a timer somewhere in a cluster with out knowing or caring about what server. And reversely, I need to be able to cancel that timer **without** having to know where in the cluster that timer lives. But before we can start to understand possible solutions, let's dive into a use case to understand the problem and why existing solutions aren't suitable replacements.
Scenarios
Un-send an email - A simple example might be providing an email service that allows people to cancel an email they have sent if it is within a 10 second window. We can't really un-send an email, but we can just not send it until our window has lapsed. Or more accurately, send it after 10 seconds giving the end user a way to cancel the act of sending. There are many ways we could do this, but for the purpose of this post - timers.
Telemarketer auto dial - A more complex example, we could consider a telemarketer using an automated dialer. Once the telemarketer has finished talking with Person A, They are given a small window of time to take some notes and dial Person B. If they don't start dialing with in the given window, the system dials the next person on the list of numbers. The act of manual dialing stops the auto-dial timer so Person C isn't dialed the same time Person B is dialed. Timers make a lot of sense here.
For these short to medium delays setTimeout is a really good fit. They are kept in memory, asynchronous, give us a rather high level of precision, deal with an arbitrary delay on an arbitrary action. More importantly we can cancel it if we want to. Simple, to the point and very easy to reason about. However, in distributed systems, we loose track of which servers are managing which timers in the event we want to cancel it. Which is the critical criteria of our solution. Let's take a look at a couple of existing solutions out there that we could utilize to work around this.
Existing solutions
Message brokers
RabbitMQ is one of the go to solutions for effectively queuing up work. But for situations like above, there are a couple of inherent problems. For one, messages are virtually impossible to delete. It just isn't apart of the AMQP protocol. Once a message goes into a queue, the only way to get it out is consume the message, or delete / purge to queue. Not really what we are after.
Message Broker
ˈmesij ˈbrōkər -n, --noun
- arrange or negotiate (a settlement, deal, or plan).
- an intermediary program module that translates a message from the formal messaging protocol of the sender to the formal messaging protocol of the receiver
Secondly, there isn't a way to delay the delivery of a message - they are consumed as fast as a consumer can pull them off the queue. This is also not really great for our use cases. Another pain point is the scalability of message brokers. While it is possible, it tends to be a bit complex.
PUB-SUB / Message Bus
This can come in various forms. I've talked about doing this with multicast. Projects I have worked on and similar projects out there take an approach with some inherent flaws.
If you are thinking that this sounds like an intentional race condition - it is
When a timer is set, the same message is broadcast to all or a limited number of nodes in the cluster, and a duplicate timer is created with a random amount of skew on the timeout. The hope here is when one of them triggers, we have enough time to broadcast another message to cancel the timer which have not triggered yet and only one of them executes. If you are thinking that this sounds like an intentional race condition - It is. So we have the ability to delay execution, but now we run the risk of executing the same timer more than once.
Another problem with using pub sub or the message bus pattern here is that as we add more nodes, the amount of traffic and work that needs to be done also goes up. If every node has to do the work of setting the timer and also look it up to cancel a timer if it is a duplicate - we don't get any performance gains by adding more nodes. It actually makes it worse.
Redis Queue
Redis has proven itself to be both very reliable and very versatile. I can be used for a wide range of technological problems. In our use case, we could use redis as a queue for timers to be set, canceled or moved in a cluster. We could have all the nodes in the cluster call BLPOP on a list key waiting for work. That would start a timer, cancel a timer or whatever it might be. BLPOP picks the least idle connection and sends it the next key in the list. This gives us exactly once delivery of messages, which is what we are after.
However, canceling becomes a problem again. We have no way of ensuring that the node that gets the message is the node that has the pending timer to be canceled, or moved to a different server, etc. You could use this in combination with pubsub or multiple list keys so certain servers are responsible for a sub set of actions. The complexity of these solutions greatly out weighs any benefit and still doesn't solve our problem. Additionally, BLPOP doesn't work like you would expect it to when you need to run redis as a cluster or behind sentinel. In these situations you run the risk of duplicated messages or missing messages all together, which puts us right back where we started. And, personally speaking, I find using your data store as a messaging layer a bit misplaced.
Skyring
These sorts of problems and frustrations are what have lead me to build Skyring - Distributed Timers as a service. Simply put - Skyring exposes a simple API into a hashring of servers to manage timers
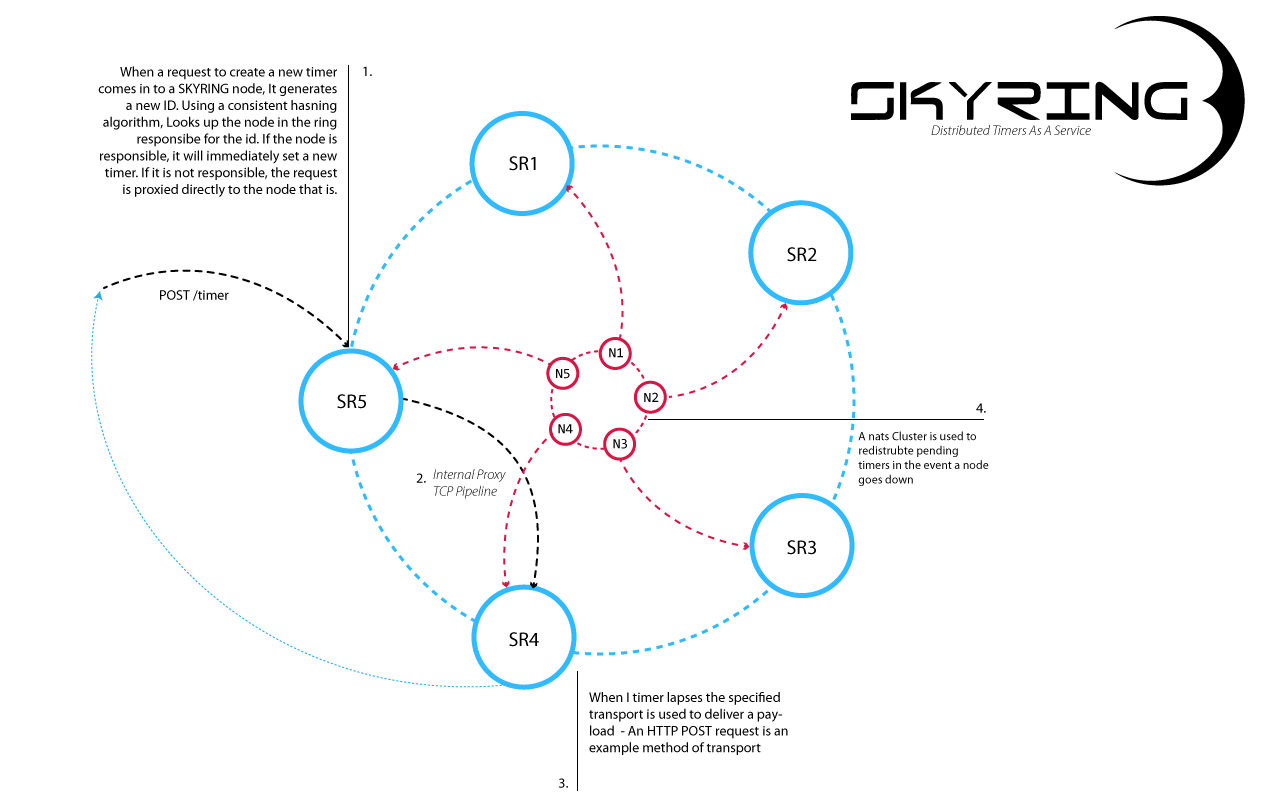
When I started building skyring, I had only a couple simple requirements.
- Simple and easy to reason about
- Ability to cancel timers
- Horizontally scalable
- Plain old setTimeout where possible
- Reliable - removing a node should not remove timers
Simplicity
Simplicity was a major driving factor. Complexity sucks. Complex systems ultimately buckle under there own weight. A dead simple API is all I want.
Set a timer
Setting a timer is as simple is making an HTTP request to the /timer endpoint to any of the nodes in a Skyring cluster.
curl -XPOST http://localhost:8080/timer -d '{
"timeout":2000,
"data": "hello world"
"callback": {
"transport": "http",
"uri": "http//api.someservice.com",
"method": "POST"
}
}'
Complexity Sucks
For performance considerations and simplicity sake, skyring will not return any data payloads. Important information is always returned in the HTTP headers. In this situation, the URI for the timer is returned in the location header.
HTTP/1.1 201 CREATED
location: /timer/4adb026b-6ef3-44a8-af16-4d6be0343ecf
Date: Fri, 23 Dec 2016 00:19:13 GMT
Connection: keep-alive
Content-Length: 0
Cancel a timer
The other critical piece to the equation is being able to cancel a timer. And it as just as simple as sending a DELETE request to the URI return in the location header
curl -XDELETE http://localhost:8080/timer/4adb026b-6ef3-44a8-af16-4d6be0343ecf
Horizontal scale
Another problem that I wanted to resolve was being able to scale the service out horizontally. Adding servers shouldn't make things slower as it tends to do with pub sub and message bus. Skyring, is a consistent hashring connected by a persistent tcp channel. As new nodes join the ring, they are responsible for only a specific portion of the timers.
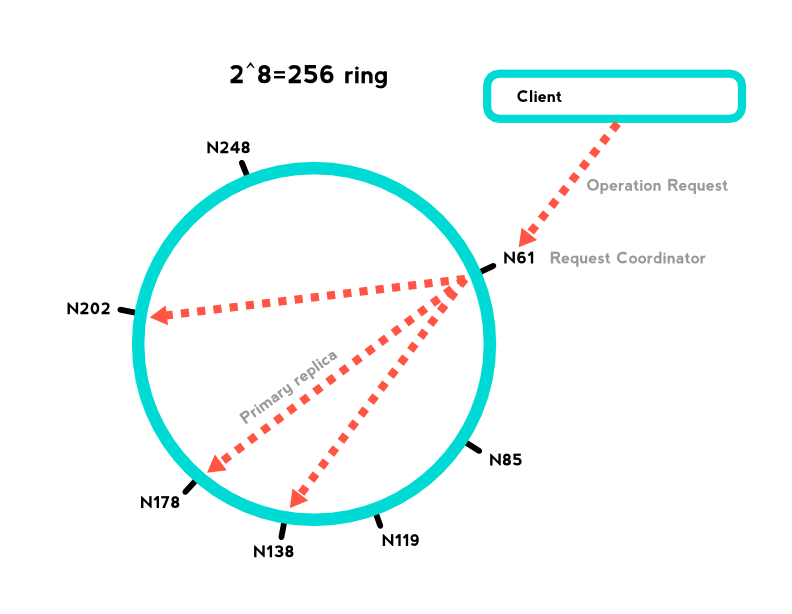
Requests can be issued to any node in the cluster. If the node the request lands on is not responsible for the key in question, it is immediately proxied to the node that is responsible over the persistent connection. That means that nothing is ever more than a single network hop away. One node or one thousand nodes - still one hop away. This is very similar to the way cassandra and other distributed data stores work. This allows skyring to keep the work load evenly spread across the cluster - CPU load, network load, event loop load, etc.
Reliable
Another problem that needs to be solved is how to deal with a node that leaves the cluster - intentionally or not. The real fly in the gravy here is we have to, both, stop accepting http requests and remove it from the internal hasring so it can stop accepting work. And we still need a way to redistribute any pending timers to the still active nodes. Under the hood, this is achieved over a nats queue group so things stay fast, but ensures exactly once delivery of messages, even in clustered setups. When a timer comes in over the nats channel it is funneled back through the normal internal machinery so the node that is now responsible for that timer gets it in, at most, 1 network hop.
Skyring makes it easy to use timers with confidence in a distributed system with a simple API providing functionality in line with setTimeout and clearTimout