Exactly Once Execution In A Distributed System
kyring is is a distributed system for managing timers, or delayed execution similar to `setTimeout` in javascript. The difference being that it is handled in a reliable and fault tolerant way. setTimeout in javascript is transient. If the running application is restarted or crashes, any pending timers are lost forever. The one guarantee that skyring provides is that a timer will execute after the specified delay, and that it only executes once. Exactly once is an interesting challenge in distributed systems, and Skyring makes use of a number of mechanisms at the node level to achieve this. From a high level, this is what the behavior on individual nodes looks like.
Shared Nothing
Skyring follows the shared nothing mantra similar to Cassandra and other distributed software systems. There is no master / slave setup. There is not a central controller or broker. Every node in a cluster is the same as the next and effectively on an island all to itself and has little insight into what other nodes might be doing. It really just knows that there are other nodes in the cluster, the ip address of the node and if it is currently active.
Every node in a cluster is the same as the next and effectively on an island all to itself and has little insight into what other nodes might be doing. It really just knows that there are other nodes in the cluster, the ip address of the node and if it is currently active.
Consistent Hashring
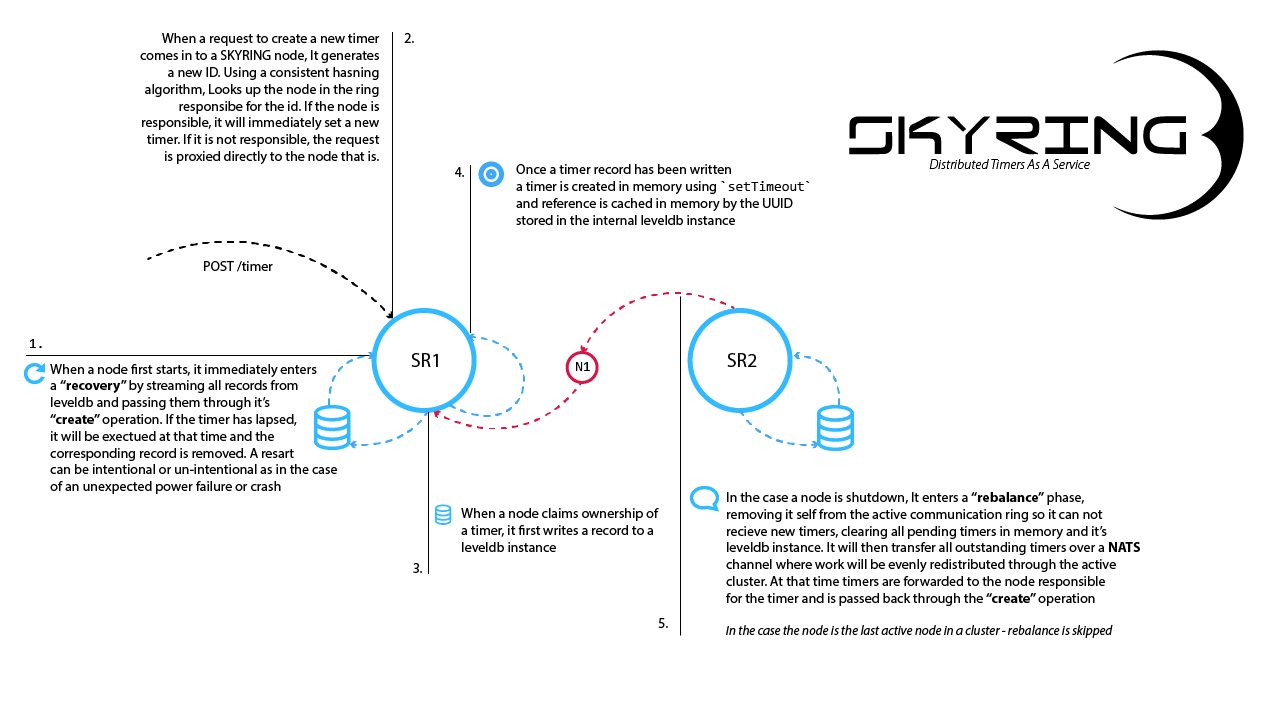
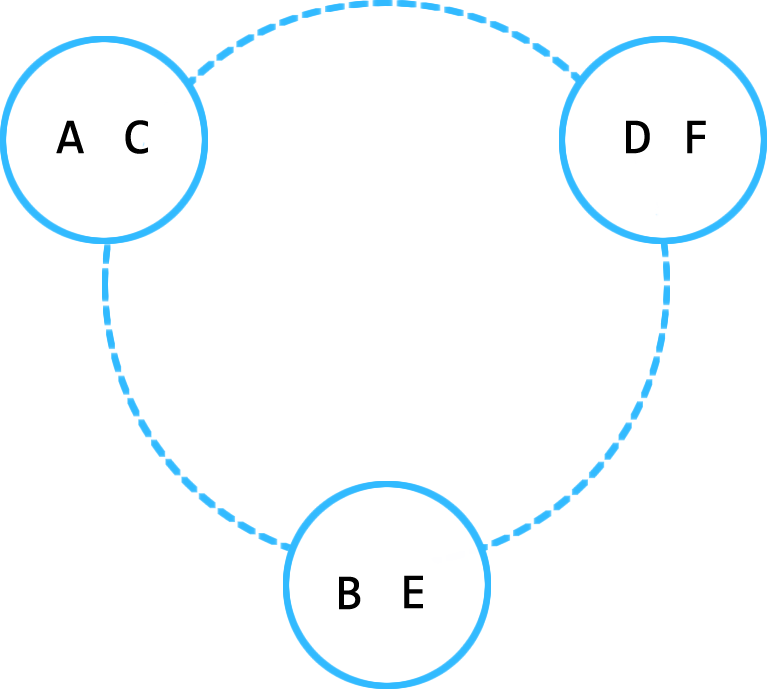
Skyring ring uses a consistent hashing to assign a specific subset of keys to specific nodes in the cluster. Nodes connect to each other using an internal tcp mesh called tchannel. When a node in the cluster handles an HTTP request for a timer, it hashes the ID and looks up the node responsible for that timer. If the node that handled the request is not the owner, it will immediately proxy the request to the node that is, and it is handled on the respective node just like every other HTTP request. The benefits gained from this are many. Most notably, is the ability horizontally scale by just starting more instances. More instances = better performance. There are no noisy neighbors in a skyring cluster. Additionally, as nodes are added, they evenly distribute the workload (memory, CPU, disk usage, etc).
Write Ahead Persistence
Internally, each skyring node uses a levelup database (w/ a leveldown backend) where timer data is stored.  Before the timer is actually started, it writes a record to leveldb so there is a disk backed record of the timer. Updates to existing timers follow the same pattern - Write to disk first. Aside from a simple persistence layer, levelup gives skyring some limited backend abstraction as levelup allows the persistence layer to be configured. Skyring itself, ships with memdown(the default) and leveldown support. But you could configure it to use rocksdb, lmdb, or any of the levelup plugins.
Before the timer is actually started, it writes a record to leveldb so there is a disk backed record of the timer. Updates to existing timers follow the same pattern - Write to disk first. Aside from a simple persistence layer, levelup gives skyring some limited backend abstraction as levelup allows the persistence layer to be configured. Skyring itself, ships with memdown(the default) and leveldown support. But you could configure it to use rocksdb, lmdb, or any of the levelup plugins.
Using an embedded database is a critical component of the system. To really achieve a shared nothing model, each node must have it's own database. More traditional central database server solutions, by their very nature, are shared; in the way that all clients connect to the same server where the data lives. If the data is shared, there is a risk of timers being executed more than once, or ownership slipping across node boundaries. With a dedicated database for each node, this is an impossibility. It also greatly simplifies the application logic as all of the data can be trusted, and all operations are reduced to simple key operations.
Internal Rebalancing
Distributing the actual timers throughout the cluster is a little tricky as timers in javascript are maintained entirely in memory. There is no in-code representation that could be used to re-create a timer. And, timers cannot be serialized in a way that would make them transferable. This makes the act of moving them from Node A to Node B a challenge. Each node will handle this in two distinct ways. The first is at the edge and is handled by the HTTP api and the internal tchannel. When An HTTP request comes with the node checks for or assigns a unique ID for the prospective timer. It hashes the ID and determines if it is responsible for that ID. if it is not, it will proxy the request over the internal tchannel. The receiving node injects the request proxy and injects it into the HTTP server, and it is handled like every other HTTP request. In that respect, timers over the HTTP API are distributed as they are handled. 
This is very similar to how a rebalance of timers is handled when a new node is added to the cluster. Say for example, we have a two node cluster and they each have some pending timers on them.
When a new node is added, we need to re-evaluate the existing timer ids in the cluster to determine if the new node should take them on. Similar to as we talked about previously, because all nodes are currently active members of the tchannel mesh we can do the following:
- Hash the timer ID
- Clear the timer from memory
- Pull & Delete the record from leveldb
- Wrap it in a mock HTTP request
- Proxy it to the right node via
tchannel
As before, when the new node receives a message over the tchannel, it is injected into the HTTP router and the server handles it as normal. When a node is removed ( intentionally or not ) some interesting things have to happen. Most importantly, the node is no longer an active member of the hashring, cannot accept HTTP requests, and is no longer connected to the tchannel mesh. It does this so it will not be sent any more work during the shutdown process that would just be lost. It also means that it cannot send other nodes the pending timers it does have over the normal avenues.
To circumvent the problem, the each node is connected to a nats cluster of one or more nats servers that it uses to publish reblanace events with timer data. Nats will round robin each event to a different node in the cluster which will perform the normal operations as laid out above. If it is responsible for the timer, it will just funnel in back through the create operations setting the timeout to the remaining time left, or executing immediately if that timer has lapsed. In the case the the node is not responsible for that timer, it will just wrap the timer data in a mock HTTP request of proxy it over the tchannel mesh. Business as usual.

As nodes leave the cluster, timers are redistributed between the active nodes in the cluster. When the last node in the cluster shuts down ( or crashes for that matter ) it will skip over the rebalance phase leaving the data in leveldb intact. When the node starts again, it will start the recovery phase.
Restart Recovery
When a node starts ( or restarts ) for the first time, before anything else, it starts streaming any and all records out of the leveldb instance. If there are any records in the DB, it is safe to assume that this node was, at one time responsible for these timers and it will immediately start passing them through the normal create operations. If the initial timer has lapsed, it will just execute the timer immediately.
Without the balance and proxy logic, the nuts and bolts of what a skyring node does, is actually very simple. In fact it comes down to about 10 lines of code - literally! It is simple enough that a first year developer could understand.
const timers = new Map()
function set(id, delay, fn) {
if (!timers.has(id)) {
timers.set(id, setTimeout( fn, delay ).unref());
}
}
function cancel(id) {
const ref = timers.get(id);
clearTimeout( ref );
return timers.delete(id);
}
Simple. Fast. Scalable