CoreOS: A Year In Review
icroservices are becoming the de-facto way of building out large applications. If you haven't worked on a project that has migrated monoliths to micro-services, you are most likely working on a microservice of some flavor or another. And as you might imagine, Docker containers are the preferred way of delivering these services. Managing all of these containers and services is no easy task and has lead to the rise of private PAaS projects, operating systems, and orchestration framewoks like Deis, Mesos, Kubernetes - A new one is popping up every month.
Choosing a framework, or a stack is, in it of itself, no simple task. Personally, I have been following CoreOS, both the company and the operating system as they seemed to be interested in solving the "Microservice Problem" from the lowest level - the operating system. More importantly, they have nearly 100 repositories on Github to solve various problems from managing clusters, to networking, to authentication, service discovery, etc. When I started working on ThreadMeUp the tech team was in the process of migrating a large, monolithic PHP application, to a suite of microservices powered by Node.js.
Early on, their deployment was, by today's standards, wrong -
- Manually Spin Up a VM on AWS
- Assign a Static IP
- Assign A DNS CNAME to The Static IP
- SSH on the the VM & Run a Chef recipe
- Generate and SSH key & Add it to a github Repo
- Git Clone A repo
- Stand up an NGINX Server w/ SSL
- Spin up an instance of Node Forever
- Watch Logs
- Hope it doesn't crash
There was no configuration, all keys, passwords etc were baked into the application. Updates were, of course, manual -
- SSH on to the server ( yes everyone had root access to prod server )
- Git Pull
- Restart Node Forever
- Watch Logs
- Hope it doesn't crash
This Sucks! Let's use Docker
If a load balancer had to be involved, each VM instance was manually added / removed. No tests, no packaging, no security - Everything is managed manually on the VM instance directly. For a monolithic application, this might be OK. Most of this is a one time thing and the rest is a periodic update. However, for microservices multiply this process out to 10-20 services where a service could be running as 5-10 of 2 or more containers - This is going to kill everyone's productivity for an entire day - if not, longer.
On my very first day of work, I said, "This sucks! Let's use docker". I knew that even moving things into containers wouldn't solve all of the problems and would even introduce some new ones; I turned to CoreOS as the platform to tackle most of those problems. Now, after a year of using CoreOS in production, I'm hear to tell my story!
If you built it, you should know how to deploy it
I will preface this by saying, I'm not a DevOps guy, not a networking guy or a security nut. I consider myself software engineer that takes the position - If you built it, you should know how to deploy it.
Before we dive into Pros, Cons & gotchas, here is a simplified bird's eye view of the infrastructure we settled into with CoreOS
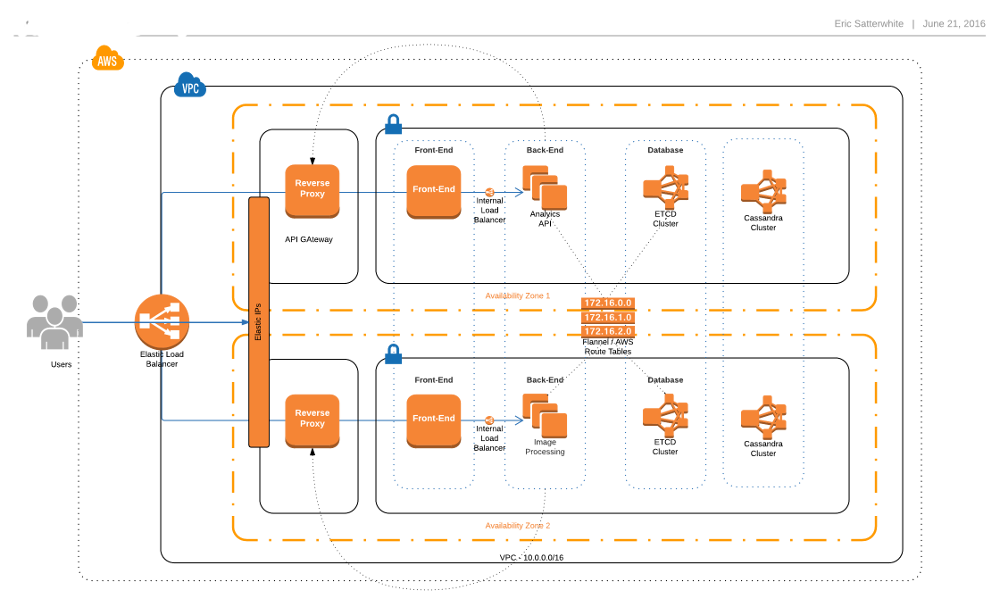
Cluster Nodes
At the lowest end of the cluster is a AWS CoreOS instance. We have 5 empty nodes that only run Etcd instances. Etcd stores all of the application level configuration. They don't do anything else, They are Database ( Etcd ) nodes. All other nodes that are brought up are configured as an Etcd proxy meaning they have a running instance of Etcd, but all commands are forwarded to one of the master nodes. Which is nice, because localhost is always a valid Etcd address. Visually our set up looked like this.
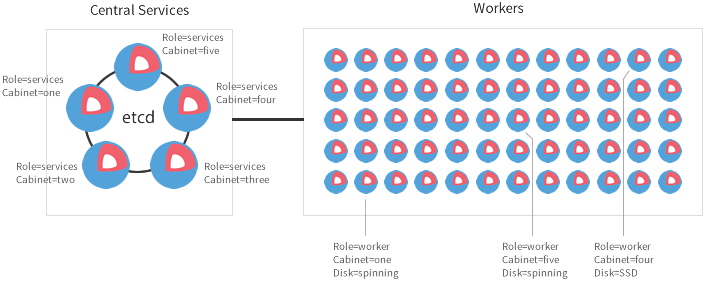
Fleet
Fleet is touted by the CoreOS team as "systemd for the cluster". Which it is in a lot of ways. But the primary use case of fleet is as the basic scheduler of work on the cluster. Work being a systemd unit which could be a long running service in a container, or a cron job. Each CoreOS machine is given a fleet configuration with machine metadata that paints a picture of the resource limits, Availability Zone, region, and general intended use of the VM. Something Like this -
metadata="class=network,cpu=2,disk=ssd,environment=staging,platform=hvm,provider=aws,ram=2GB,region=west,role=api,space=15GB,zone=2b"
With this, we can define services that target a class of VMs by resource, AZ, class, in any combination. This way we never have to have to use static IP, or know where a given service is running. As long as there is a VM that fulfills the metadata requirements, Fleet will make sure it gets there.

Flannel Is the network overlay from CoreOS. It allows direct container-to-container communication via the internal IP of the container. All of the CoreOS machines are configured to run flannel using the AWS route-tables plugin. For the most part this is hands off once the VPC is configured with an IP block.
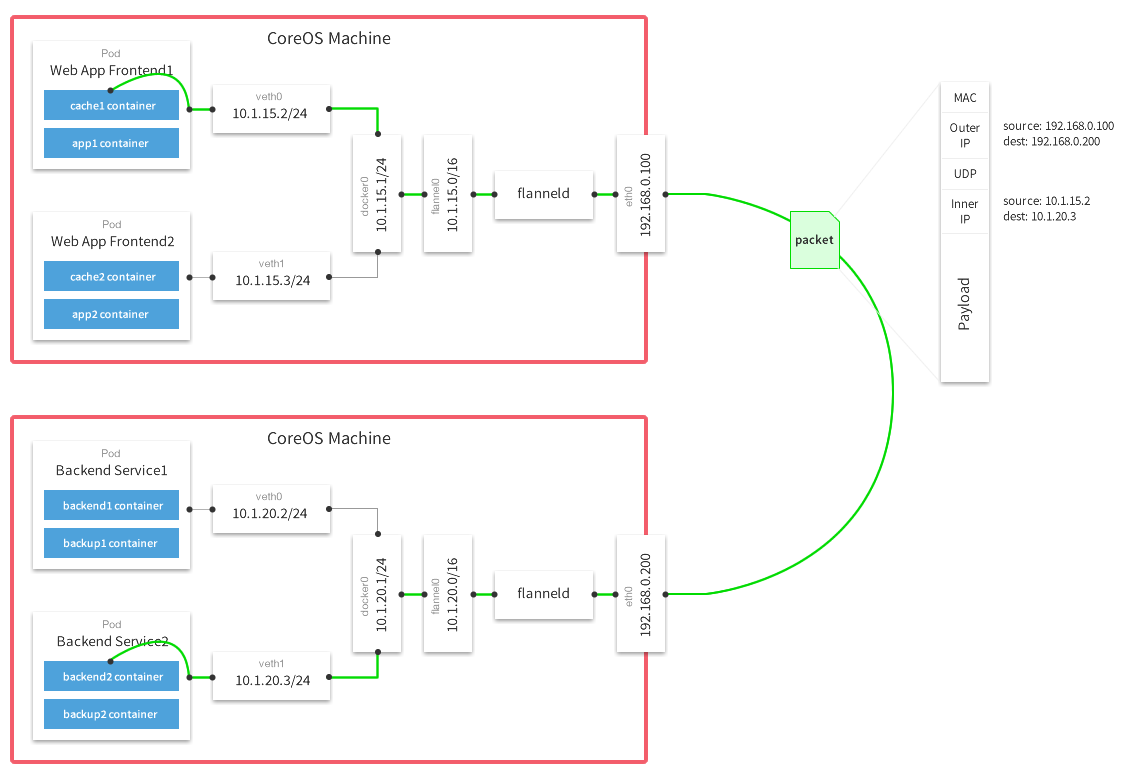
This allows us, again, to stay naive about static IPs, public IPs or DNS names. Services can register with the discovery tier by the private IP address inside the container, and everything is fine.
Global Configuration
There are certain pieces of information that we need to make available to our services as they are starting up. Things like Load balancer names, Static/HOST IPs, data center / region, AWS Keys and the such. Things that don't change very often, but may very based on the VM. To deal with that I employed a global unit that ran once when the VM booted and wrote out a config file.
All we need to do is configure ETCD, and we are mostly done.
[Unit]
Description="Bootstraps the Environment file and extracts credientails into /etc/release.env"
Requires=etcd2.service
After=etcd2.service
Wants=fleet.service
After=fleet.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/usr/bin/sh -c "/usr/bin/echo ETCD_NAMESPACE=fulfill >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n CASSANDRA_SEEDS= >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/etcdctl get /fulfill/metadata/cluster/cassandra/seeds | tr -d [:space:] >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n '\n' >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n KONG_HOSTS= >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/etcdctl get /fulfill/metadata/cluster/kong/hosts | tr -d [:space:] >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n '\n' >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n KONG_ELB= >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/etcdctl get /fulfill/metadata/common/aws/elb/kong | tr -d [:space:] >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n '\n' >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n UI_ELB= >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/etcdctl get /fulfill/metadata/common/aws/elb/fulfill | tr -d [:space:] >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n '\n' >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n ENVIRONMENT= >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/etcdctl get /fulfill/metadata/common/environment | tr -d [:space:] >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n '\n' >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n RELEASE_CHANNEL= >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/etcdctl get /fulfill/metadata/common/release/channel | tr -d [:space:] >> /etc/release.env"
ExecStart=/usr/bin/sh -c "/usr/bin/echo -n '\n' >> /etc/release.env"
[X-Fleet]
Global=true
It isn't the prettiest thing in the world, but it pulls data from ETCD, the AWS metadata endpoints and generates a file that all other services will use as the bases for the shell environment when they execute. So all we need to do is configure Etcd, and we are mostly done. This is defined as a global unit which means every time a new machine enters the cluster, this unit will automatically be scheduled. In other words, our config file just auto generated for us. Nice!
API Gateway

At the edge was a single Load Balancer that sits in front of an API Gateway - We were using Mashape's [Kong](https://getkong.org). A single DNS `A record` of `api.threadmeup.com` was assigned to the Load Balancer which balanced instances of kong. This was the public entry point into the cluster. I did end up assigning Static IPs to these mainly because they were public facing, down time was not an option and it just makes managing nodes easier.
## Side Kicks
For anything that needed a load balancer - Kong, services, etc. They were deployed with what people have been calling sidekick units. These are services that are a dependency of a different service. When The main service starts, the side kick starts. When the main service stops, the sidekick stops. Our sidekicks added / removed services to known load balancers ( aws elb ) by name. Pretty simple. It is more boiler plate work, they are almost all the same.
API Services
Once all of this other stuff is in place, services are rather easy, Any configuration is dumped into ETCD, and that drives start up behavior. In a nutshell, if there is any configuration present for Kong services use that information to register themselves as service. Simple. Fleet figures out where the services go, and will account for machine failures ( restart / destroyed, etc ).
Everything runs in a a container, so we don't need to do any complex provisioning of new VMS, we can mostly copy the last one that was started and call it a day. Services can come / go - Machines can come / go; It doesn't matter.
The Good
There are some things I really liked about CoreOS. Given than I used a pretty vanilla setup CoreOS out of the box, I got a lot of mileage out of it.
Modern Linux Kernel
CoreOS keeps up with the latest stable ( and secure ) linux kernel releases and those will be applied automatically for you. Ubuntu / Debian have always been a little bit behind the curve on that front.
Quay
We used Quay to host our private Docker images. We didn't want to run our own registry but needed a private solution. Quay provides on the fly security audits of all the images you host which we used a good deal to update packages where needed. More Over, unlimited storage. Our Continuous Integration servers would auto deploy images as build artifacts and had a set of tags for each of the deployment environments ( development, staging and production ). Developers could just run a single command to get new nightly builds of whatever.
docker pull somservice:development
Cloudinit
CoreOS uses cloud init to bootstrap CoreOS machines. It is a YAML file and allows you to do just about everything you would normally need to do - write out files, define services to start, configure networking, etc. In most situations, this came down to copy & paste with a tweak to some metadata, or in the case of AWS - using the more like this feature on EC2 instances. It was dead simple.
Systemd
CoreOS uses systemd for everything. Service definitions for fleet look like systemd unit files. Even the tools they provide look and feel like Systemd tools( foo and fooctl ). Most everything that ships with the OS can be overridden / configured / disabled with unit files which can be written with a cloud-init config.
I'm Not Afraid To Write These
In almost every situation, this comes down to configuring flannel and writing authentication credentials for docker. Additionally, Most unit files for microservices come down to 5-6 lines of mostly docker commands
[Service]
User=core
Restart=on-failure
RestartSec=5
EnvironmentFile=/etc/release.env
ExecStart=/usr/bin/docker run --rm -h %p ${RELEASE_CHANNEL}%i -p 3300:3300 -e PORT=3300 -e KONG_SYNC=true -e KONG_HOST=${KONG_HOSTS} -e NODE_ENV=${ENVIRONMENT} --name=%p-%i service:${RELEASE_CHANNEL}
ExecStop=/usr/bin/docker pull quay.io/threadmeup/memphis:${RELEASE_CHANNEL}
ExecStop=/usr/bin/docker stop -t 60 %p-%i
ExecStopPost=-/usr/bin/docker rm %p-%i
This is far easier to understand than upstart / initd scripts or chef recipes. These are very declarative, and I'm not afraid to write these. More importantly, someone other than the person who wrote it can also understand it.
Docker First
The entire CoreOS ecosystem focuses on containers. While they have released there own container run time called rkt that follows the appc spec, which I like, and is also easier to instrument / automate than docker as there is no client / server set up like with docker. But Docker is more mature, has better tooling, and has a better community.
While CoreOS machines have some familiar *NIX tools installed ( vim, git, curl, jq, less ), there are no build tools, no package manager, nothin . If you want to install something on these machines, it is going to be in a container or you'll have to SCP binaries on to each machine.
ETCD Everywhere
Every node has Etcd running by default. Every node knows about every node, and configuring one node via ETCD means you are technically configuring them all. That is pretty awesome.
Remote Fleet Admin
Fleet is a distributed init system and comes with fleetctl to interact with it. What is cool about this, is that you can use fleetctl from your local computer to interact with a remote cluster.
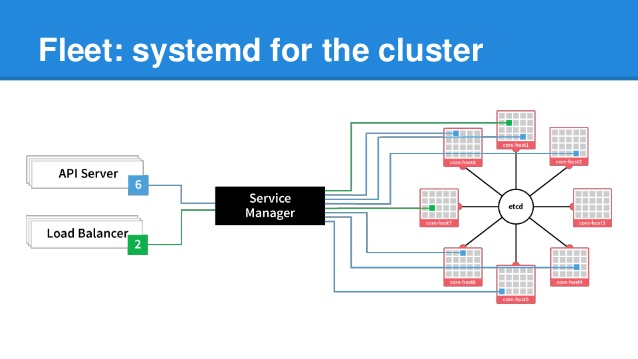
You don't have to assign IPs to secure nodes or copy keys around to ssh into everything. You can start / stop remote services, add new ones, replace old ones. And if you really need to you can use fleet to ssh into machines running specific services. Generally speaking, this solves the problem of every developer having to have root ssh access to every VM in the cluster or having to remember IP addresses of the VM where a specific service is running. We can just execute fleet commands from a random lap top. In practice, we actually designated one of the empty ETC nodes as the control node and that was the only machine ( at a network level ) that was allowed to issue fleet commands.
fleetctl stop myservice
fleetctl start myservice
fleetctl status myservice
# tail the logs
fleetctl journal -f myservice # similar to tail -f for services
fleetctl ssh myservice
Yes, that one 5-6 line unit file gets you all of that. It is that simple. This simplistic interface into the operating system makes automating via a CI service very straight forward.
Flannel
The network mesh provided by flannel does a lot of dirty work for you and smooths over a lot of the rough edges with networking between containers. It does so much smoothing over, that you really don't need to worry about it! Every container is reachable by internal ip from any other container in the cluster. No linking, no mounting, no docker swarm, no docker networks. Just "Set it, and Forget It". When CoreOS is running smoothly, the only thing you really care about is hardware - Make sure there are enough Machines in the cluster to accommodate your apps.
The Bad
CoreOS brings a lot of goodness to the table, but there are some rough edges and I have run into a good number of them.
Resource Awareness
Fleet, which is responsible for scheduling your services / containers on machines in your cluster has no insight into if it actually can run your service on a machine based on available resources ( RAM, disk space, etc ). If you have a VM with 512 MB of memory and 100mb of disk space, fleet would gladly try to run 100 different containers on your tiny VM.
I Don't Know
You will have to come up with a way to manage that yourself. I tried to go the Fleet Metadata route , but that only gets me so far. Which brings me to the next point
No Feedback
$ fleetctl start service@{1..10}
service@1 started
service@2 started
service@3 started
service@4 started
service@5 started
service@6 started
service@7 started
service@8 started
service@9 started
service@10 started
Which service failed to start due to low memory? I don't know. Which service was rescheduled, but there was no machine for it to run on? I Don't know. Which service failed to start because docker machine was unable to allocate an IP address? I. DON'T. KNOW. Fleet only tells you if it was able to successfully execute the command to start the service. That doesn't mean the service actually started, it doesn't mean the service isn't in a crash loop and every time you ask fleet for a status check, it looks like the service is running.
The real bummer here is that the only thing you are able to do is hop on to the VM and drudge through the journal ( syslog-ish ) for some indication as to why a particular container can't start. In a lot of situations, it may not actually be in the journal or obvious as to what the problem is and the only thing you can do is try to execute the command from the unit file and hope you get an error. Because fleet won't do that for you. Shitty. Real shitty. This also means if you are using fleet through some kind of continuous deployment mechanisms, there is no direct way to determine if the deployment was successful or not. Also - Real shitty.
Monitoring
CoreOS is a distributed OS whose focus centers around managing large clusters of machines and services. This is all fine and good, but gives you no insight into the health of your cluster. Even the basics: CPU, Disk Space / Usage, Memory - All a black box. You will have to bring your own monitoring to the table. However, even if you do that, it probably won't have hooks for the fleet scheduler and you will still be left to hold fleets hand to direct it make some smart decisions.
Auto Updates
Now, the folks at CoreOS are pretty up front about how the OS deals with updates, being that they are automatic. If not disabled, when a new stable release is issued, the OS will download it, apply it and reboot. This causes any services scheduled by fleet to be rescheduled on to new machines. And given that fleet has no sense of available resources, this can cause problems. A lot of problems. Rule of thumb - Disable locksmithd, the service that tracks updates. This can be done in your cloud-init.
So Many Files
Everything is a service and all services need at least 1 unit file for fleet. Need a side-kick? two files. Want to run a cron job? 1 unit to define what is going to happen, 1 unit file to define a cron schedule. In a decently sized application, it adds up. Quickly. This is really more a mechanism of Systemd and linux in general than it is CoreOS, but you can't have one with out the other. Especially when so many of your units are so similar, it can be tedious and a lot to keep track of.
ETCD Cluster Admin
For the non proxy nodes, each of the nodes needs to know about the others and all proxy nodes need to know the addresses of the non-proxy nodes. For initial bootstrapping of a new cluster, CoreOS provides a service to generate a discovery URI which etcd will use to do IP address resolution. Great. However, that URL is 1 use only, after that, you are on your own. If a node goes down, needs to be replaced, or whatever, it isn't always a simple as just getting it back up. If the IP address change for whatever reason, you will have to re-configure the cluster to accommodate a new node by removing the old and adding in the new.
What is the most frustrating about this, is that if you were using a discovery URL, chances are you never paid much attention to the internal IP addresses of the original node and it will be a tedious job of checking each of the machines to get an IP and doing a manual configuration of one or more nodes. This also applies if you want to expand the size of your cluster - say from 3 to 5 nodes. That sucks. It really draws you in with the easy initial setup and basically leaves you out to dry.
Recap
In all, I was very pleased with what CoreOS provides - They deliver on what they have promised. They are very upfront and transparent about known problems and steer you away from certain setups or products all together if they don't believe them to be production ready. Moreover, I do not consider myself a devops person or a system admin, and was able to get this all working in a fairly short amount of time. I was actually able replace the entire monolithic application setup in production running on ubuntu whole-sale with the new CoreOS setup, and no one noticed ( which is good ). It went pretty smooth. If I ever find myself somewhere that is introducing docker I would absolutely recommend CoreOS as the OS to run things on. However, I would also be much more pro-active about filling in the gaps with some kind of orchestration framework.
CoreOS: It's pretty good.